在先前的硕士课程 Advanced Deep Learning 中,我们的课程作业带来了一个极其硬核且紧跟前沿的课题—探索 Meta AI 提出的颠覆性视觉基础大模型:Segment Anything Model (SAM) 。
SAM 在计算机视觉领域的地位,就如同 GPT 在自然语言处理领域的地位一样。它通过海量数据(1100 万张图片,超 11 亿个掩码的 SA-1B 数据集)的洗礼,实现了强大的 Zero-shot(零样本)泛化能力,并引入了优雅的 Promptable Segmentation(可提示分割) 范式。
然而,SAM 原论文主要在自然场景数据集上进行训练和评估。作为一名严谨的学习者,我产生了一个巨大的疑问:当号称能“分割一切”的 SAM,面对它极少见过的、对比度低且缺乏自然特征的医学 X 光(X-ray)图像时,它还能保持神奇的魔力吗?
这篇博客既是我的课程学习日记,也是一次技术复盘。我将带大家从阅读 SAM 论文开始,体验 Web 端的交互分割,到使用 Python 探索 Prompt Engineering,最后自己动手搭建 YOLOv8 动态提示(Dynamic Prompting)+ SAM 的全自动流水线,并与传统的 U-Net 进行一场“终极对决”。
代码链接:Segmenting Lung X-ray Images with the Segment Anything Model
1. 理论碰撞:SAM 能胜任医疗 X 光分割吗?
在动手敲代码之前,作业的第一步要求我们基于原论文《Segment Anything》评估 SAM 在医疗 X-ray 肺部提取任务上的预期表现。我的理论分析如下:
- 挑战在于领域差异(Domain Gap): 医学 X 光图像与自然图像存在巨大鸿沟。X 光片是灰度图,对比度低,且包含许多需要专业医学先验知识才能辨别的细微解剖结构。SAM 作为通用模型,没有经过大规模医疗数据的专门微调,在处理复杂的器官边界时可能会“水土不服”。
- 潜力在于极强的泛化(Generalizability): SAM 的核心卖点是其强大的零样本适应能力。得益于在海量数据上学习到的底层边缘、形状和连通区域特征,只要我们能给出精准的提示(Prompt,如明确的点或框),它极大可能具备克服领域差异的能力。
初步结论: 我预期 SAM 能给出一个相当不错的 Baseline,但极度依赖于高质量的提示(Prompt)。
2. 浅尝辄止:Web Demo 上的交互式分割初体验
俗话说实践出真知,我首先在 SAM 官方 Demo 网站 上上传了几张验证集的肺部 X 光片,分别体验了三种不同的 Prompt 方式:
- 点提示(Point Prompting):
提供了极高的控制力。可以通过不断添加绿点(前景)和红点(背景)来引导模型,精细修正边界。缺点是费时费力,如果初始点选得偏,生成的初始掩码会很不理想。 - 边界框提示(Bounding Box Prompting):
体验极佳!针对肺部这种大型解剖结构,画一个大致的框,SAM 瞬间就能利用全局上下文(Context)捕捉到器官边界,初始分割效果往往比单点好得多且速度更快。 - 全自动模式(Automatic Mode):
全自动生成,但在 X 光片上简直是“灾难现场”。由于缺乏明确的医学语义目标,它把肺部、心脏、肋骨、背景仪器切成了无数个毫无意义的细碎小块,产生严重的过分割。
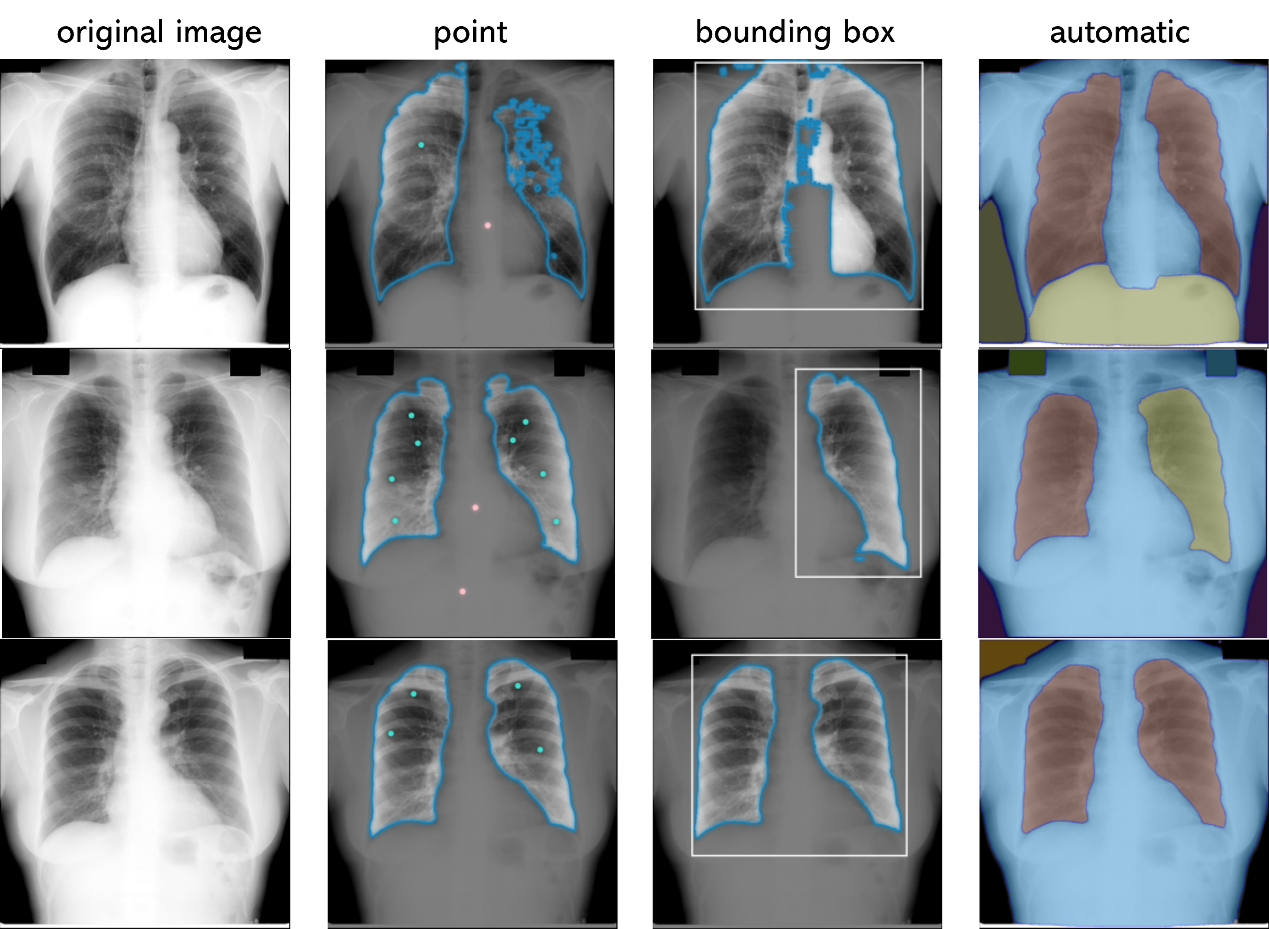
这也印证了我的猜想:SAM 在医学图像上是有效的,但必须有人工或算法的精确引导。
3. 代码实战:Python 里的静态 Prompt Engineering
体验完 Demo,真正的硬核挑战开始了。我们在 Jupyter Notebook 中使用 Python API 来调用 SAM 处理验证集。
策略 A:启发式点提示 (Point Prompt)
我为单侧肺部精心设计了固定的坐标提示点组合:4个前景点(如 [75, 100], [80, 75], [180, 75], [185, 100])加上 1个背景点(位于纵隔区域 [135, 150] 以防溢出)。
优化 Trick:Mask 级联预测
为了获得最佳结果,我利用了 SAM 输出多候选掩码的特性:首先让模型初步预测,提取置信度(Score)最高的那个 Mask,然后 将其作为下一次预测的输入先验(Input Mask) 进行细化打磨。
- 验证集结果:Mean F1-Score = 0.9084,Std = 0.0247
对于一个未经任何医疗数据微调的 Zero-shot 模型,仅靠 5 个固定坐标点就能在肺部提取上达到 90% 以上的 F1 分数,不仅精度高而且表现极其稳定!
策略 B:真实边界框提示 (Ground Truth BBox Prompt)
基于 Web 端的经验,我写了一个脚本,利用真实分割掩码(Ground Truth)通过 OpenCV (cv2.boundingRect) 提取出极其准确的边界框,并将其作为 Prompt 喂给 SAM。最后采用 np.logical_or 合并左右肺的输出。
- 验证集结果:Mean F1-Score = 0.9177,Std = 0.0248
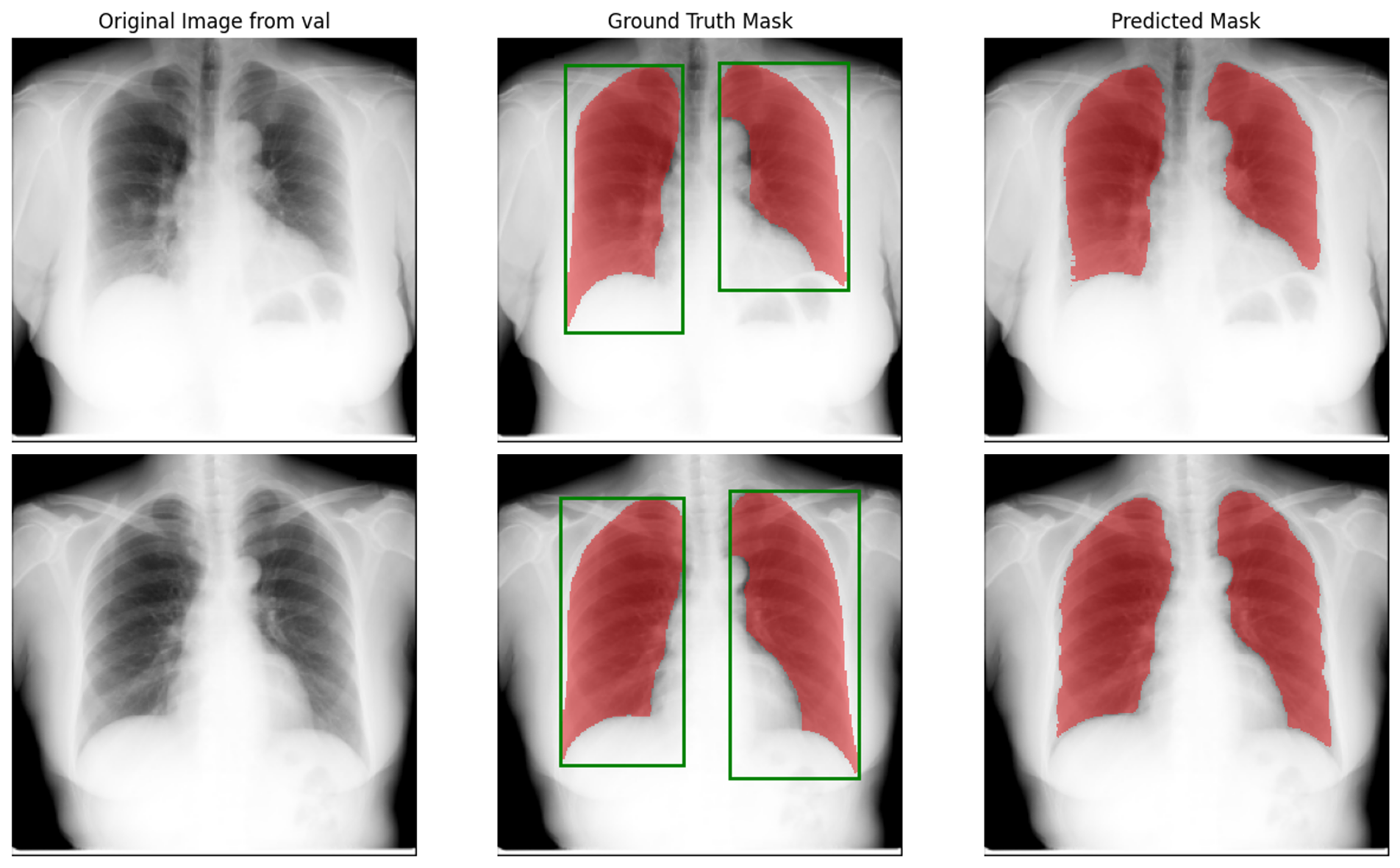
代码实验感悟: 边界框(BBox)为 SAM 提供了比散点更明确的全局空间约束,有效排除了医学图像中的噪声干扰,因此 F1 分数获得了进一步提升。
4. 终极形态:动态提示流水线 (YOLOv8 + SAM)
静态点和真实框提示虽然得分高,但在实际临床的自动诊断中,医生不可能一张张图去打点,我们也没有 Ground Truth 可以提取框。有没有办法实现完全的端到端自动化?
这就是本次作业的终极进阶:动态提示(Dynamic Prompting)。既然框提示效果最好,那我们为什么不训练一个轻量级的目标检测网络,让它自动找出肺部的 Bounding Box,再喂给 SAM 呢?
我的全自动流水线设计如下:
- 训练检测器 (YOLOv8): 使用上一步从 GT 中提取的边界框作为标签,我专门训练了一个 YOLOv8 目标检测模型(跑了 250 个 Epochs)。它的任务很简单:学会在 X 光片中定位双肺。事实证明它做得极好,在测试集上的 Mean IoU 达到了 0.9364。
- 强强联手 (YOLOv8 -> SAM): 给定一张全新的 X 光图 $\rightarrow$ YOLOv8 预测边界框 $\rightarrow$ 将其作为动态 Prompt 传给 SAM $\rightarrow$ SAM 零样本输出高精度精细掩码。
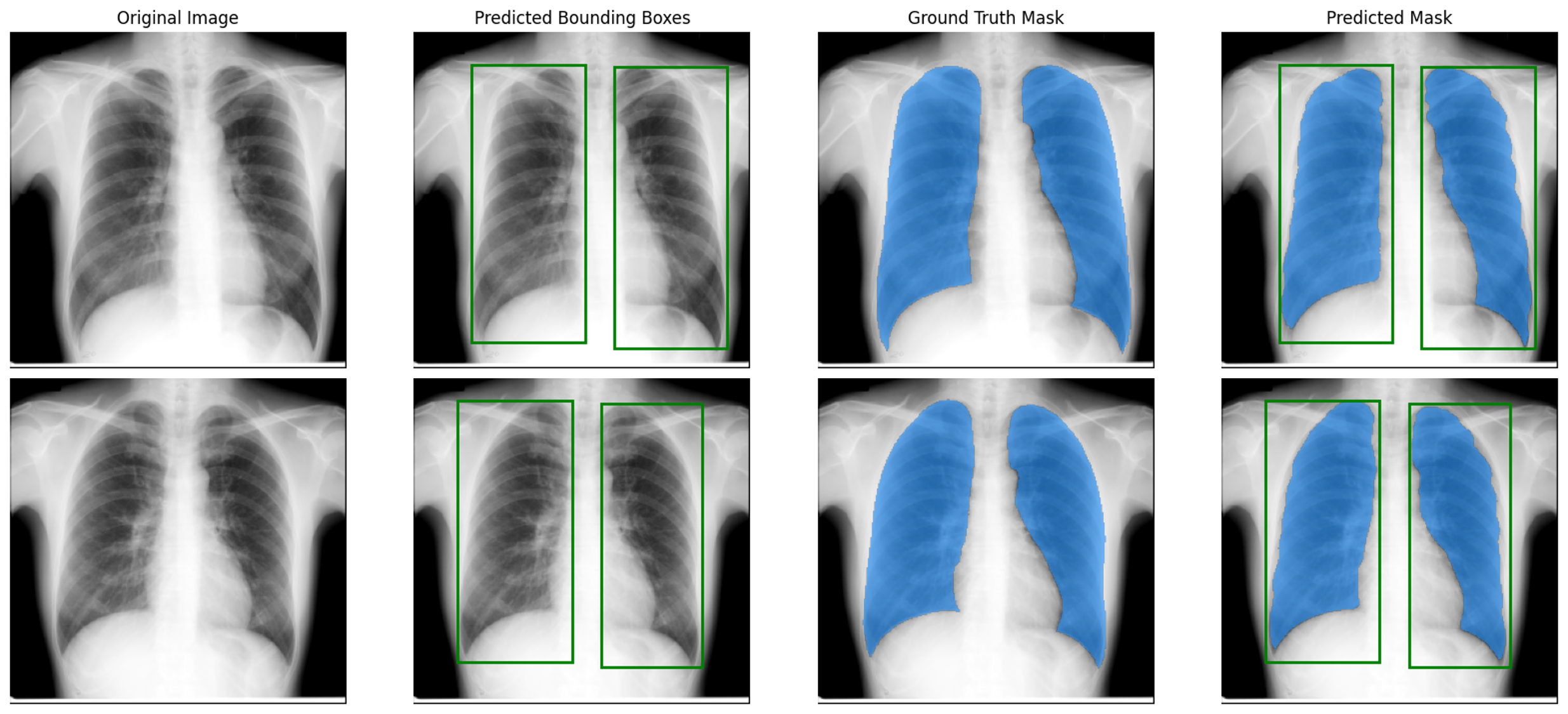
终极对决
在这门课的先前任务中,我们曾完全从零开始手工训练了一个经典的 U-Net 来做肺部自动分割。现在,让我们看看“基础大模型”带来的降维打击(在测试集上的表现):
| 分割方法 / 模型 | 提示机制 | Mean F1-Score | Standard Deviation |
|---|---|---|---|
| Vanilla U-Net | 全监督端到端训练 | 0.6073 | 0.0901 |
| SAM (Zero-shot) | 静态点提示 (Points) | 0.9084 | 0.0247 |
| SAM (Zero-shot) | 真实框提示 (GT BBox) | 0.9177 | 0.0248 |
| YOLOv8 + SAM | 动态框提示 (Dynamic) | 0.9233 | 0.0280 |
核心结论剖析:
- 对传统小模型的绝对碾压: 相比于辛辛苦苦从头训练的 U-Net(F1 仅有 0.6073,且极不稳定 Std=0.0901),基于大模型的 YOLOv8+SAM 管道在精度(0.9233)和鲁棒性(Std=0.0280)上实现了彻底的降维打击。
- 分工明确的优雅架构: YOLOv8 + SAM 取得了全场最高分!YOLOv8 完美弥补了 SAM 缺乏特定医学先验的短板,充当了“放射科专家”的眼睛(高精度定位);而 SAM 充分发挥了它强大的通用基础能力,担当了“像素级描边大师”。两者结合,在不对 SAM 进行任何权重微调的情况下,实现了极高质量的自动化医学分割。
5. 总结与反思
通过这次 Advanced Deep Learning 课程的深度探索,我对计算机视觉领域正在发生的 范式转变(Paradigm Shift) 有了切肤之感。
过去,面对一个新的医学图像分割任务,我们总是苦于收集大量精细的像素级标注数据,耗时耗力去从零训练或微调一个 U-Net。
而在 Foundation Models(基础大模型) 时代,视觉任务也正在不可逆转地走向 Prompt Engineering(提示工程)。
SAM 展现出了一个强大底层视觉引擎的魅力。“轻量级目标检测模型 (Task-specific) + 通用分割大模型 (General)” 的解耦架构展现出了巨大的落地潜力。我们只需要极低的成本训练一个 YOLO 来充当“提示器”,繁重的抠图工作直接交给 SAM 即可。
虽然在极个别肺尖或肋膈角的模糊细节上,SAM 仍有一丝偏移,但瑕不掩瑜。Segment Anything 名副其实,它为深度学习在医疗垂直影像领域的落地,开启了一个激动人心的新范式!
感谢阅读!本文为哥本哈根大学 Advanced Deep Learning 课程作业复盘与个人探索记录。如果你也对视觉大模型在医疗领域的应用感兴趣,欢迎联系我一起探讨交流!


